Datastandardizer
Data Standardizer in Master Data Management Solution
This paper desribes our approach to address data quality problems for our product IBM Product Master. I woudln’t say that this approach solves all the data quality problems, works all the time and would work for all too. Just that this approach is taking us ahead and we are continuing to improve the features.
This article was presented @GHCI2021 and also won the white paper challenge @IntuitWiTech.

Introduction
Data quality is utmost important in Master Data Management (MDM) solutions. The Import/export features bring data in bulk. This data contains many inconsistencies. Data inconsistencies could be typos, colloquial acronyms, non-standardized variants etc. MDM Customers are from varied domains such as retail, telecom, pharmaceuticals, manufacturing. Each customer has specific data naming conventions. Suppliers/third-party vendors do not adhere to such conventions. They import products with inconsistent naming patterns, including typos in the data fields. A team of merchandizers, supplier managers, product managers and catalog editors spend multiple cycles curating the data before it gets on-boarded on catalogs.

Standardizing incoming data manually is a major customer pain point that we look to solve.
The research questions we solve are:.
- Can we build a solution that standardizes the data for every customer without hand crafting rules for each of them?
- Can we ensure that ‘nike’ gets corrected to ‘nice’ for all customers except ‘Nike’ customer?
- Can this solution be domain portable?
Related Work
Statistical based Peter Norvig’s spell corrector is a popular approach. However, it becomes computationally intensive when a word has more than 3 chars out of place. With advancements in NLP and Deep Neural Network (DNN)s, this problem could be solved by embedding meaning into the words. Word2Vec and GloVe pretrained model learnt from billions of words and phrases provide embeddings. However, more than 40% of words in our dataset, fell out of vocabulary (OOV) from these pretrained models. This impaired any further work on using pretrained word embeddings.
We explored state-of-the-art techniques in NLP to build a neural machine translation where a non-standardized sentence provided by supplier gets translated to a standardized version. The results were promising but DNNs come with their own challenges. More details in the experiments section. For our use case, the vocabulary was much smaller and strictly based on closed domains. The variations and typos were related to only these vocabulary words. We thus, moved on to build a simple model that learns its context from the data and picks up patterns of standardization.
Experiments and Results
Datasets
We crawled the product details from catalogs on public websites for 3 customers from pharmaceutical, retail and electronic domains. The datasets consisted of 10K product descriptions with an average of around 10 words in each description.
Experiments
To train DNNs, noise was added on datasets (typos such as phonetic errors (‘great’, ‘g8’ and iphone, ifone), misplaced chars, standardization errors) and a corpus containing both error and it’s expected version of sentences was built. For our tests, we compared results/ performance on 3 approaches.
- A char based seq-2-seq encoder decoder model with bidirectional LSTM and attention.
- Attention based Transformers
- Our approach (described in Approach section next)
Results
The encoder decoder model learned standardization patterns well. However, the limitations could not be ignored.
- For training the model, samples of non-standardized versions are required along with the expected version of the samples.
- The results showed that variation types learnt for a word, are not applied to other words. Depicting bad examples for every possible case was not possible.
- It did not handle typos well.
- The results showed bias towards the examples which were present more in quantity than the rest, implying the training set very sensitive to the imbalance in qunatity of examples.
- We additionally saw regressions when correct words were getting replaced undesirably. With attention-based transformers, the results were much better wrt regressions seen. Typos were handled better, and the bias though existed, was less than the encode decoder models. We faced another challenge though. To handle OOV words, char-based model was used. The response time became a show stopper with transformers for cases with larger sentences (>10 words). After trying sota techniques, we moved on to a simple approach. With it, our training time and response time have improved. Synthetic noisy data generation is not required. We saw major improvement in fixing typos, unseen variations with no regression on correct content.
Approach
We apply a two-stage process to build a robust model that outperforms all the state of art techniques on our chosen datasets. In the first stage, a neural network learns the contextual meaning of words in the data. Given ‘n’ context words (window size = n), it predicts top m words that comes in the same context. In the second stage, similarity of the predicted words with the misspelt/non-standardized word is computed, to zero down on the replacement.
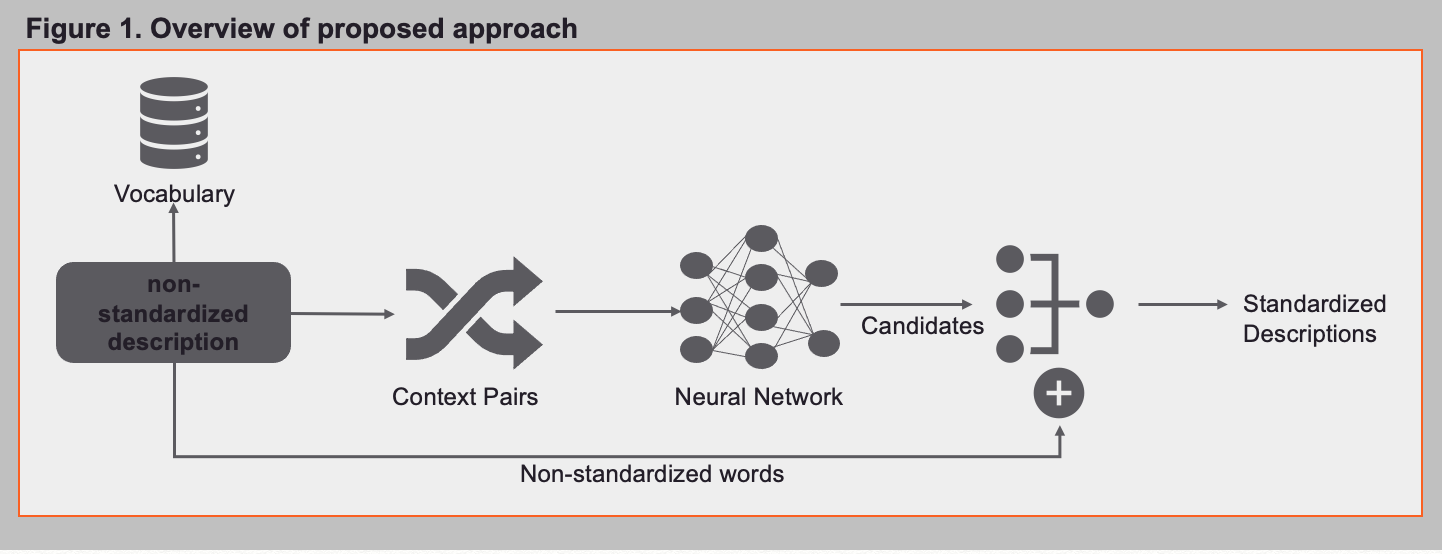
Stage 1 :
- Build a vocabulary of words in the dataset.
- For every word, create pairs of size n to capture context.
- Train a neural network that predicts a word, given context words
- We use this model to recommend top m probable candidate words, given a context of words for replacing detected non-standardized word(s)
Stage 2 :
- Choose the most similar word to the OOV word, within a fixed threshold.
- We used the edit distance to compute similarity, which worked better than cosine similarity. Using an ensemble of similarity algorithms helps based on the use cases in domains.
- If none of the recommended words match within a set threshold with the detected non-standardized word, the word was left as is and the record was marked for manual review.
Conclusion
This solution can easily learn complex patterns and mitigate the challenges of building a DNN.
- For training deep Learning models, examples of both non-standardized and standardized sentences are required. Availability of non-standardized examples is a huge challenge as no customer collects this data. Generating synthetic negative data might not be representative of real time usages leading to degraded results in production. Not only does our proposed solution learns only from the good samples, but also is very effective with unseen data nuances.
- Unlike any DNNs, the two-stage process adopted also weighs in the runtime presented non-standardized word in deciding the final recommendations.
- This model has proven effective across domains with very small training set.
Contributions
Google Word2vec model is trained on 3 billion words. This training is on news dataset which is totally different to the domain we are working in. Through our work, we share a very important learning to all our practitioners that more than using a latest sophisticated technique, focus must be on understanding our systems, its’ needs and available data. This understanding will help bring out solutions that are efficient, cost-effective and best fit. Our model is lighter than the latest deep learning models, has outperformed them on our tests and gives similar results across different domains. We have successfully integrated this model in our product as data standardization feature that went live on May 2020.
References
[1] Peter Norvig: https://norvig.com/spell-correct.html
[2] Stanford GloVe: https://nlp.stanford.edu/pubs/glove.pdf
[3] Google Word2Vec: https://arxiv.org/pdf/1310.4546.pdf
[4] The Annotated transformer: https://nlp.seas.harvard.edu/2018/04/03/attention.html
[5] Sequence to Sequence Learning with Neural Networks: https://arxiv.org/pdf/1409.3215.pdf
[6] Google’s Neural machine Translation System: https://research.google/pubs/pub45610/.